El objetivo de Google Research es trabajar para resolver problemas ambiciosos y a largo plazo, sobre todo, aquellos que ayudarán de manera significativa a las personas en su vida diaria. Con ese objetivo, en 2019 realizamos avances en varias áreas de investigación fundamentales; expandimos nuestro trabajo a otras nuevas y emergentes, como el cuidado de la salud y la robótica; ofrecimos una amplia variedad de códigos de carácter abierto, y continuamos colaborando con los equipos de productos de Google a fin de desarrollar herramientas y servicios que ahora son mucho más útiles para los usuarios.
Con el inicio de 2020, es bueno dar un paso atrás para evaluar el trabajo que hicimos el año pasado, pero también miraremos hacia adelante para ver los problemas que intentaremos resolver en el futuro. Inspirada por ese espíritu, esta entrada de blog es una visión general de algunos de los proyectos de investigación que hicieron los investigadores y los ingenieros de Google durante 2019 (similar a las de 2018 y a las de 2017 y 2016, que fueron algo más detalladas). Para ver un panorama más detallado, consulta nuestras publicaciones de investigación de 2019.
Uso ético de la IA
En 2018, publicamos un conjunto de Principios de IA, que brindaban un marco de trabajo para evaluar nuestras propias investigaciones y aplicación de tecnologías, como el aprendizaje automático, en nuestros productos. En junio de 2019, publicamos una actualización anual para detallar cómo ponemos en práctica estos principios en diversos aspectos de nuestras investigaciones y los ciclos de vida de desarrollo de nuestros productos. Como varios de los sectores que abarcan estos principios son áreas activas de investigación de la IA general y la comunidad de aprendizaje automático (como sesgo, seguridad, legitimidad, responsabilidad, transparencia y privacidad de los sistemas de aprendizaje automático), nuestros objetivos son aplicar en nuestro trabajo las mejores técnicas conocidas en la actualidad en estas áreas y realizar investigaciones para continuar con los avances de vanguardia en ellas.
Por ejemplo, este año hicimos lo siguiente:
- Publicamos un artículo de investigación sobre una nueva herramienta de transparencia, que habilitó el lanzamiento de Model Cards para varios de nuestros productos de IA de Cloud. Consulta esta tarjeta de modelo de ejemplo para la función «Detección de objetos» de la API de AI Vision de Cloud.

- Mostramos cómo Activation Atlases puede ayudar a explorar el comportamiento de redes neuronales y asistir en la interpretabilidad de modelos de aprendizaje automático.
- Presentamos TensorFlow Privacy, una biblioteca de código abierto que permite entrenar modelos de aprendizaje automático con garantías de privacidad diferencial.
- Lanzamos una versión Beta de Fairness Indicators para ayudar a practicantes de aprendizaje automático a identificar impactos injustos o no intencionales en sus modelos.

Hacer clic en una porción de Fairness Indicators cargará todos los puntos de datos de esa porción en el widget de la herramienta What-If. En este caso, se muestran todos los puntos de datos con la etiqueta «female». - Publicamos un artículo de KDD’19 sobre cómo se incorporaron comparaciones de pares y regularización en el sistema recomendador de producción a gran escala para mejorar la legitimidad del aprendizaje automático.
- Publicamos un artículo de AIES’19 sobre un caso de éxito de aplicación de legitimidad en la investigación de aprendizaje automático en un sistema de clasificación de producción y describimos nuestra métrica de legitimidad, «igualdad condicional», que tiene en cuenta las diferencias de distribución en la implementación de igualdad de oportunidades.
- Publicamos un artículo de AIES’19 sobre la legitimidad basada en los hechos en problemas de clasificación de texto que plantea la pregunta «¿Cómo cambiaría la predicción si el atributo sensible al que se hace referencia en el ejemplo fuera diferente?» y usa este enfoque para mejorar los sistemas de producción que evalúan la toxicidad del contenido en línea.
- Publicamos un nuevo conjunto de datos para mejorar la investigación sobre identificación de ultrafalsos.

Muestra de videos sobre la contribución de Google en la comparativa FaceForensics. Para generarlos, se seleccionaron pares de actores al azar, y redes neuronales profundas intercambiaron sus caras.



IA para beneficencia social
El aprendizaje automático tiene un enorme potencial para resolver muchos problemas sociales importantes. Trabajamos en varias áreas y ayudamos a muchas otras a aplicar sus habilidades y creatividad para resolver esos problemas. Las inundaciones son el desastre natural más común y peligroso del planeta, ya que afectan a cerca de 250 millones de personas todos los años. Mediante aprendizaje automático, procesamiento y mejores fuentes de datos, logramos mejorar de manera significativa la predicción de inundaciones a fin de enviar alertas de acción a los teléfonos de los millones de personas que viven en las regiones afectadas. También brindamos un taller que reunió a investigadores expertos en predicción de inundaciones, hidrología y aprendizaje automático de Google y la comunidad científica general para buscar formas de ampliar la colaboración en torno a este problema.

Además de trabajar en la predicción de inundaciones, desarrollamos técnicas para comprender mejor la vida salvaje del mundo; para ello, colaboramos con siete organizaciones de conservación de fauna a fin de usar el aprendizaje automático en el análisis de datos sobre vida salvaje tomados con cámaras, así como con NOAA (Administración Nacional Oceánica y Atmosférica, EE.UU.) para identificar especies de ballenas y localizarlas a partir de sonidos de grabaciones submarinas. También creamos y lanzamos una serie de herramientas que permiten realizar nuevos tipos de investigaciones sobre biodiversidad mediante aprendizaje automático. Con el fin de ayudar a organizar el 6.º taller de categorización visual detallado, investigadores de Google de nuestra oficina en Accra, Ghana, colaboraron con investigadores del grupo de investigación relacionada con IA y ciencia de datos de Makerere University para crear y celebrar una competencia de Kaggle en torno a la clasificación de las enfermedades de la planta de mandioca. Como la mandioca es la segunda fuente más grande de hidratos de carbono en África, la salud de esta planta es un problema de seguridad alimentaria importante, y fue increíble ver que el concurso atrajo a más de 100 participantes, reunidos en 87 equipos.
En 2019, actualizamos la línea de tiempo de Google Earth a fin de que los usuarios puedan visualizar de manera intuitiva y efectiva cómo cambió el planeta durante los últimos 35 años. Además, colaboramos con investigadores académicos en nuevos métodos de protección de la privacidad para agregar datos sobre movilidad humana que brinden a los planificadores urbanos información sobre cómo diseñar entornos eficientes que reduzcan los niveles de emisión de dióxido de carbono.
También implementamos el aprendizaje automático para mejorar el aprendizaje de los niños. De acuerdo con las Naciones Unidas, hay 617 millones de niños analfabetos, lo que constituye un factor determinante en su calidad de vida. Para que los niños aprendan a leer, la app de Bolo usa tecnología de reconocimiento de voz que orienta a los estudiantes en tiempo real. Y, para extender su acceso, la app funciona completamente sin conexión en teléfonos de gama baja. En India, Bolo ya ayudó a 800 000 niños a leer historias y pronunciar 500 millones de palabras. Los primeros resultados son prometedores: el piloto de tres meses, que se llevó a cabo en 200 aldeas de India, mostró que el 64% de los participantes mejoraron sus habilidades de lectura.
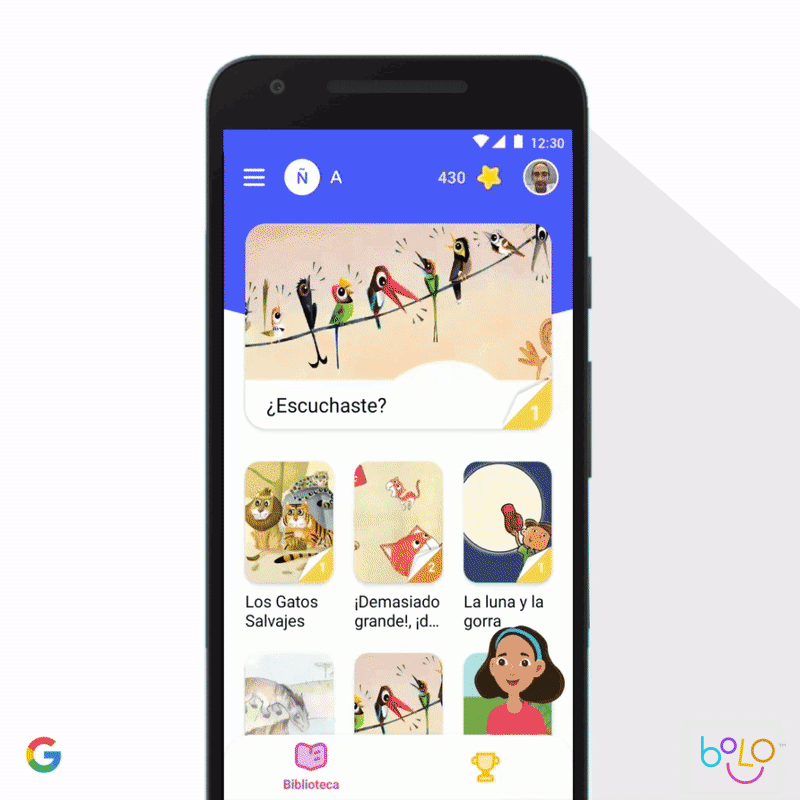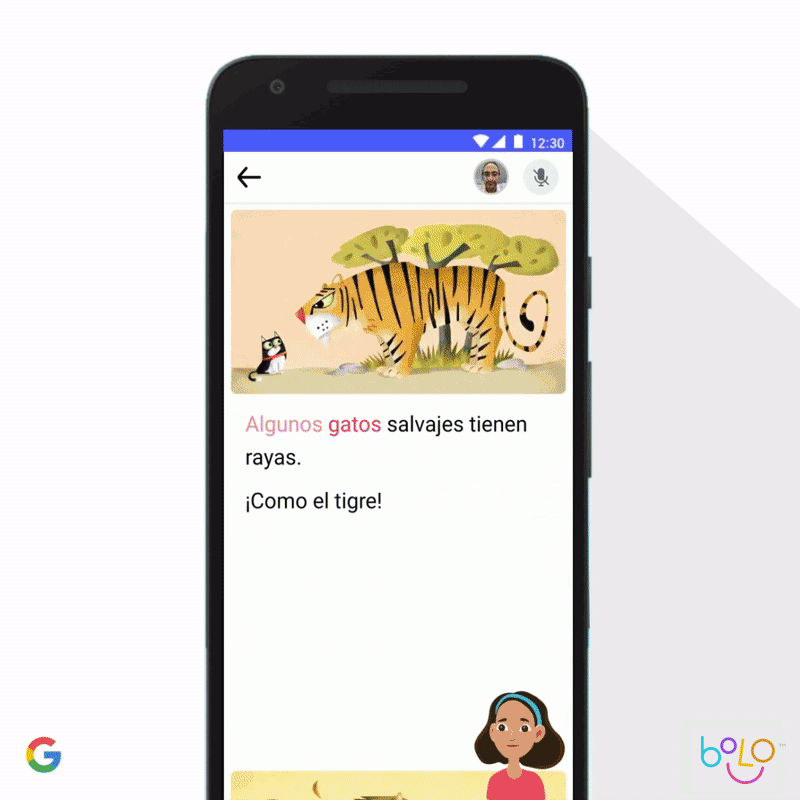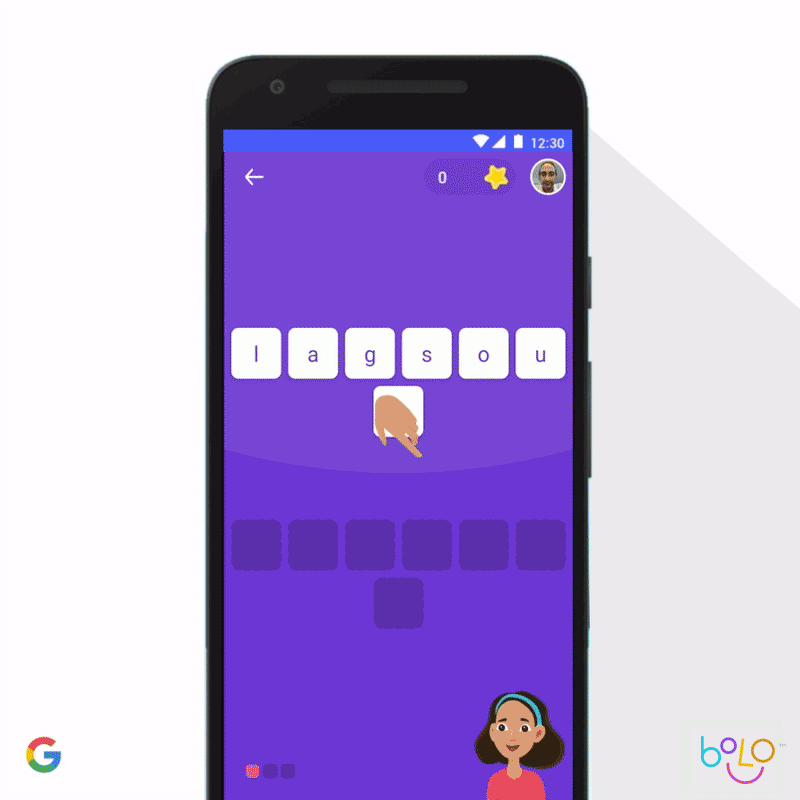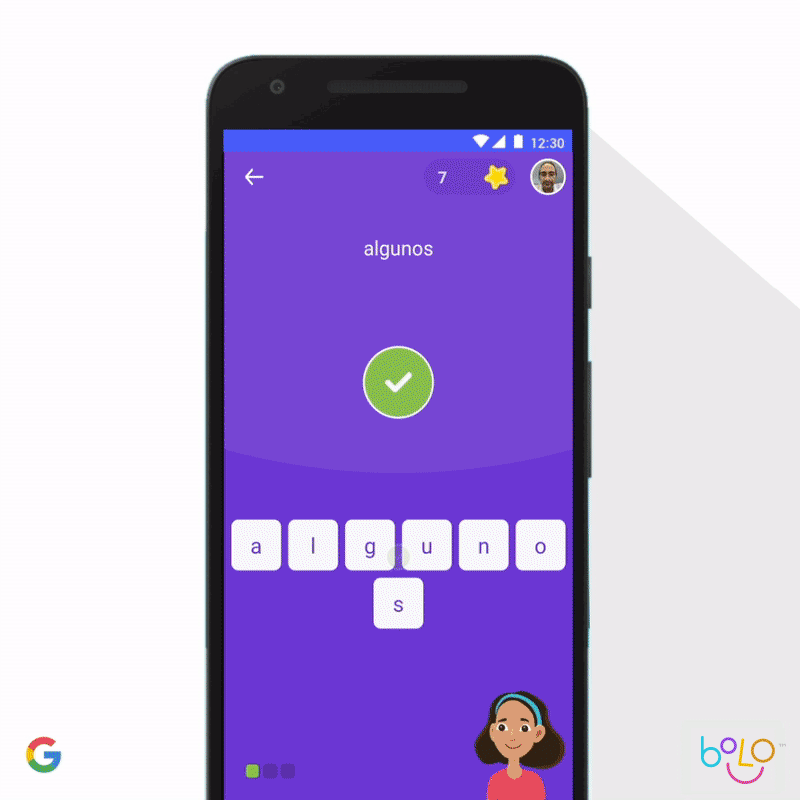
Por otro lado, la app de Socratic puede ayudar a estudiantes de secundaria con problemas complejos de matemática, física y más de 1000 temas de educación superior. En función de una foto o pregunta verbal, la app identifica automáticamente los conceptos relacionados y muestra vínculos a los recursos en línea más útiles. Al igual que con el método socrático, la app no responde directamente las preguntas, sino que guía a los estudiantes para que las encuentren por su cuenta. Nos entusiasma pensar en las posibilidades de mejorar los resultados de la educación en todo el mundo que ofrecen herramientas como Bolo y Socratic.
Para extender el alcance de nuestros esfuerzos de IA para beneficencia social, en mayo anunciamos a los beneficiarios de nuestro Impact Challenge de IA, que entregará 25 millones de dólares en subsidios de Google.org. La respuesta fue masiva: recibimos más de 2600 propuestas interesantes de 119 países. Entre los solicitantes, veinte increíbles organizaciones se destacaron por su potencial para resolver grandes problemas sociales y ambientales, por lo que se convirtieron en las primeras beneficiarias. Ejemplos del trabajo de estas organizaciones:
- La Fundación Médicos sin Fronteras (MSF) está creando una aplicación para smartphones gratuita que usa herramientas de reconocimiento de imágenes para ayudar al personal médico que trabaja en entornos de bajos recursos (actualmente, se está realizando la prueba piloto en Jordania) a analizar imágenes de agentes antimicrobianos a fin de encontrar los antibióticos que deben usarse para la infección de cada paciente.
- Más de mil millones de personas viven en granjas y trabajan como pequeños agricultores. Por lo tanto, incluso el ataque de una única peste puede acabar con sus cosechas y sustento. Wadhwani AI usa modelos de clasificación de imágenes para identificar pestes y brindar información oportuna sobre los pesticidas que deben usarse y en qué momento a fin de mejorar el rendimiento de las cosechas.
- Por otro lado, en las selvas tropicales, donde la deforestación ilegal actúa como principal responsable del cambio climático, Rainforest Connection usa aprendizaje profundo para administrar supervisión bioacústica y teléfonos celulares antiguos para realizar el seguimiento del estado de la selva y detectar amenazas.

Los 20 ganadores del Impact Challenge de IA. Puedes obtener más información sobre el trabajo de los beneficiarios aquí.

Aplicaciones de la IA en otros campos
La aplicación de la informática y el aprendizaje automático en otros campos científicos es un área que nos entusiasma, por lo que publicamos varios artículos relacionados, con frecuencia en colaboración con varias organizaciones. Estos son algunos destacados del año:
- En Reconstrucción interactiva, automatizada en 3D del cerebro de una mosca,informamos sobre un trabajo colaborativo que logró un hito en el mapeo de la estructura completa del cerebro de una mosca aplicando modelos de aprendizaje automático que lograron trazar cada neurona individual.

- En Aprendizaje de métodos de simulación mejorados para ecuaciones en derivadas parciales, mostramos cómo puede usarse el aprendizaje automático para acelerar el cálculo de EDP, que son fundamentales para la resolución de problemas de procesamiento relacionados con climatología, dinámica de fluidos, electromagnetismo, conducción de calor y relatividad general.

Simulaciones de la ecuación de Burgers, un modelo de ondas de shock en fluidos, resueltas con un método de volumen finito estándar (izquierda) o con nuestro método basado en redes neuronales (derecha). Los cuadrados naranjas representan las simulaciones realizadas con cada método en cuadrículas de baja resolución. El modelo se retroalimenta con estos puntos en cada punto de tiempo, lo que luego predice cómo cambiarán. Las líneas azules muestran las simulaciones exactas que se usaron para el entrenamiento. La solución de la red neuronal es mucho mejor, incluso en una cuadrícula 4 veces menos detallada, como lo indican los cuadrados naranjas que definen claramente la línea azul. - Además, les dimos a los modelos de aprendizaje automático mejores ejemplos de aromas del mundo con Aprendizaje olfativo: Uso del aprendizaje profundo para predecir las propiedades olfativas de las moléculas. Mostramos cómo implementar redes neuronales gráficas (GNN) para predecir directamente los descriptores de olor de moléculas individuales sin usar reglas creadas manualmente.
- En este trabajo, que combina la química con un refuerzo de las técnicas de aprendizaje, presentamos un marco de trabajo para la optimización de moléculas.
- El aprendizaje automático también puede ayudar en proyectos artísticos y creativos. Varios artistas encontraron formas de colaborar con IA y RA, y crearon interesantes manifestaciones nuevas, como el baile con una máquina para reimaginar coreografías y la creación de nuevas melodías con herramientas de aprendizaje automático. Sin embargo, los principiantes también pueden usar el aprendizaje automático. Para homenajear el nacimiento de J. S. Bach, usamos un doodle que implementaba aprendizaje automático: si el usuario creaba una melodía, la herramienta de aprendizaje automático podía crear armonías para acompañarla con el estilo de Bach.


 |
| Instantánea en 2D de nuestro espacio de incorporaciones, en el que se destacaron algunos ejemplos de olores. Izquierda: Cada olor tiene un espacio propio. Derecha: La naturaleza jerárquica del descriptor de olor. Las áreas sombreadas y delineadas se procesan con una estimación de la densidad kernel de las incorporaciones. |
Tecnología asistencial
En una escala más personal, el aprendizaje automático puede ayudarnos en la vida diaria. Es fácil dar por sentada nuestra capacidad de ver una imagen increíble, escuchar nuestra canción favorita y hablar con nuestros seres queridos. Sin embargo, más de mil millones de personas no tienen acceso al mundo de esta manera. La tecnología del aprendizaje automático puede convertir estas señales (visuales, auditivas y verbales) en otras que puedan detectar las personas con necesidades de accesibilidad, lo que les brinda un mejor acceso al mundo que las rodea. Ejemplos de nuestra tecnología asistencial:
- Lookout ayuda a las personas ciegas o con visión reducida a identificar información sobre su entorno. Depende de una tecnología similar a la que sustenta Google Lens, que permite realizar búsquedas y acciones en torno a los objetos que rodean al usuario apuntándolos con el teléfono.
- Transcripción instantánea tiene el potencial de permitir que las personas sordas o con deficiencias auditivas tengan una mayor independencia en sus interacciones diarias. Estos usuarios pueden obtener transcripciones de sus conversaciones en tiempo real, incluso aunque el discurso sea en otro idioma.
- Project Euphonia realiza transcripciones de voz a texto personalizadas. Para las personas con ELA y otras condiciones que alteran o dificultan el habla, esta investigación mejora el reconocimiento automático de voz en comparación con otros modelos de ese tipo más modernos.
- Al igual que Project Euphonia, Parrotron usa redes neuronales de extremo a extremo para mejorar la comunicación, aunque la investigación se centra en la conversión automática de voz a voz, en lugar de la transcripción, puesto que presenta una interfaz de voz a la que algunos usuarios quizá puedan acceder más fácilmente.
- Hay millones de imágenes en línea que no tienen descripciones de texto. La función Obtener descripciones de imágenes de Google ayuda a usuarios ciegos o con visión reducida a comprender las imágenes que no tienen descripciones. Cuando un lector de pantalla encuentra una imagen o un gráfico sin descripción, Chrome crea una automáticamente.
- También desarrollamos herramientas que pueden leer texto visual en formato de audio en Lens para Google Go, lo que ayuda significativamente a los usuarios que no saben leer bien a navegar en el mundo repleto de palabras que los rodea.
Logramos que tu teléfono sea más inteligente
Gran parte de nuestro trabajo está destinado a dispositivos personales inteligentes, ya que les brindamos a los teléfonos móviles nuevas funciones aprovechando su aprendizaje automático incorporado. Mediante la creación de poderosos modelos que puedan ejecutarse en el dispositivo, podemos asegurarnos de que las funciones de estos teléfonos sean altamente responsivas y siempre estén disponibles, incluso en modo de avión o sin conexión de red. También progresamos en la obtención de modelos de reconocimiento de voz, modelos visuales y modelos de reconocimiento de escritura a mano de alta precisión de manera completa en el dispositivo, lo que abrirá el camino para increíbles funciones nuevas. Estos son algunos de los destacados de este año:
- Lanzamos el subtitulado incorporado en el dispositivo mediante Subtitulado instantáneo, que siempre proporciona transcripciones de cualquier video que se reproduce en tu dispositivo.

- Creamos la nueva y poderosa app de transcripción Grabadora, que puede indexar información de audio fácilmente a fin de que sea fácil de obtener.
- También realizamos mejoras en la traducción con cámara de Google Traductor para que los usuarios puedan apuntarla a texto en idiomas que no saben y obtener traducciones en contexto al instante.

- Lanzamos la API de Augmented Faces en ARCore, lo que habilita nuevas herramientas de expresión en RA en tiempo real.

- Realizamos una demostración del seguimiento de una mano sobre un dispositivo en tiempo real, lo que habilita nuevos métodos de interacción y control de dispositivos con la mano para los usuarios.

- Mejoramos el reconocimiento de escritura a mano basado en RNN en el dispositivo para teclados en pantalla de dispositivos móviles.
- Por otro lado, lanzamos un nuevo enfoque de localización global que usa la cámara de los smartphones para orientar a los usuarios de manera más precisa y ayudarlos a moverse en el mundo.






El aprendizaje federado (lee la descripción del cómic en línea) es un método de aprendizaje automático que inventaron investigadores de Google en 2015, con el cual varios clientes (como dispositivos móviles y hasta organizaciones enteras) pueden entrenar un modelo en colaboración sin perder la descentralización de los datos. Esta herramienta habilita enfoques que tienen propiedades de privacidad superiores en sistemas de aprendizaje a gran escala. Cada vez usamos el aprendizaje federado en más productos y funciones y, al mismo tiempo, trabajamos en soluciones de vanguardia para varios problemas de investigación con este método. En 2019, investigadores de Google colaboraron con autores de 24 (!) instituciones académicas para producir un artículo general sobre el aprendizaje federado, en el que se destacaron los avances de los últimos años y se describieron varios problemas sin resolver en el campo.
Durante los últimos años, el campo de la fotografía computacional permitió realizar grandes avances en la calidad de las imágenes que toman las cámaras de los teléfonos. Este año no fue la excepción, ya que facilitamos la toma de selfis increíbles, la de imágenes de campos y retratos con profundidad de carácter profesional y el uso de Visión nocturna en teléfonos Pixel para hacer alucinantes tomas de astrofotografía. Puedes encontrar más detalles técnicos sobre este trabajo en artículos sobre superresolución multifotograma y fotografía con dispositivos móviles en condiciones de muy poca luz. Todo este trabajo ayuda a los usuarios a tomar fotos increíbles para recordar los momentos mágicos de la vida.

Salud
A fines de 2018, combinamos al equipo de salud de Google Research, DeepMind Health y un equipo de la división de Hardware de Google dedicado a las aplicaciones relacionadas con la salud con el fin de formar Google Health. En 2019, continuamos con la investigación que iniciamos en este espacio y publicamos artículos de investigación y herramientas de compilación en colaboración con una variedad de socios de cuidado de la salud. Estos son algunos de los destacados de 2019:
- Demostramos que un modelo de aprendizaje profundo para mamografías puede asistir a los médicos en la detección del cáncer de mama, enfermedad que afecta a 1 de cada 8 mujeres en EE.UU., con una precisión mayor que la de los expertos, lo que reduce tanto los falsos positivos como los falsos negativos. El modelo tuvo una precisión similar al entrenarse con datos anónimos de un hospital del Reino Unido para evaluar pacientes en un sistema de salud completamente diferente del de EE.UU.

Ejemplo de un caso de cáncer difícil de detectar que fue correctamente identificado por aprendizaje automático - Demostramos que un modelo de aprendizaje profundo para diagnósticos diferenciales de enfermedades de la piel puede dar resultados significativamente más precisos que una revisión general de un médico o incluso de un dermatólogo.
- Trabajando con expertos del Departamento de Asuntos de Veteranos de EE.UU., colegas de DeepMind Health que ahora son parte de Google Health demostraron que un modelo de aprendizaje automático puede predecir el inicio de la insuficiencia renal aguda (IRA), una de las principales enfermedades prevenibles, hasta dos días antes de su aparición. En el futuro, esta herramienta les daría a los médicos una ventaja de 48 horas para comenzar a tratar esta grave afección.
- Expandimos la aplicación del aprendizaje profundo a los registros de salud electrónicos junto a varias organizaciones socias. Puedes leer más al respecto en nuestra entrada de blog de 2018.
- Dimos un gran paso hacia la predicción del cáncer de pulmón, ya que trabajamos con un modelo de aprendizaje profundo que examinó los resultados de un estudio de tomografía computada con la misma eficacia (o incluso mejor) que un radiólogo para detectar esta enfermedad en sus primeras etapas. La detección temprana del cáncer de pulmón mejora significativamente la posibilidad de supervivencia.

- Seguimos expandiendo y evaluando nuestra implementación de herramientas de aprendizaje automático para la detección y prevención de enfermedades oculares, en colaboración con Verily y nuestros socios de cuidado de la salud de India y Tailandia.
- Publicamos un artículo de investigación sobre un microscopio de realidad aumentada para el diagnóstico del cáncer, en el que un patólogo puede obtener comentarios en tiempo real sobre qué partes de una muestra de tejido son más interesantes cuando la examina por el microscopio. Puedes obtener más información al respecto en nuestra entrada de blog de 2018.
- Creamos una herramienta de búsqueda de imágenes similares centrada en seres humanos para que los patólogos puedan brindar diagnósticos más efectivos mediante el examen de casos similares.


Informática cuántica
En 2019, nuestro equipo de informática cuántica demostró por primera vez que una tarea de procesamiento puede ejecutarse exponencialmente más rápido en un procesador cuántico que en una de las computadoras clásicas más rápidas del mundo: 200 segundos contra 10 000 años.
 |
| Izquierda: Interpretación de un artista del procesador Sycamore montado en el criostato (versión en resolución completa; Forest Stearns, artista cuántico de IA residente de Google). Derecha: Fotografía del procesador Sycamore (versión en resolución completa; Erik Lucero, científico investigador y director de producción de hardware cuántico) |
El uso de computadoras cuánticas puede resolver problemas importantes en dominios como las ciencias materiales, la química cuántica (ejemplo anterior) y la optimización a gran escala. Sin embargo, para que esto sea una realidad, tenemos que seguir logrando avances en el campo. Ahora estamos concentrándonos en la implementación de correcciones de errores cuánticos a fin de extender el tiempo de ejecución de los procesamientos. También estamos trabajando para facilitar la expresión de los algoritmos cuánticos y el control del hardware, y encontramos nuevos métodos de uso de técnicas de aprendizaje automático clásicas, como el aprendizaje de refuerzo profundo para crear procesadores cuánticos más confiables. Los logros de este año son inspiradores y representan los primeros pasos en el camino para que la informática cuántica práctica sea una realidad para la resolución de una amplia variedad de problemas.
También puedes leer la opinión de Sundar sobre lo que representan nuestros hitos en la informática cuántica.
Teoría y algoritmos generales
En las áreas generales de algoritmos y teoría, continuamos con nuestra investigación en fundamentos algorítmicos y aplicaciones, y también trabajamos en análisis de grafos y trading algorítmico. Esta entrada de blog resume parte de nuestro trabajo en los algoritmos de aprendizaje de grafos y brinda más detalles al respecto.
Publicamos un artículo de VLDB’19 titulado «Balanceo de carga basado en caché en aplicaciones de centros de datos«, aunque un título alternativo podría haber sido «Aumenta un 40% la capacidad de funcionamiento de tu centro de datos con este truco genial». En este artículo, se describe cómo usamos particionamiento balanceado de grafos para especializar la caché en nuestro sistema de servidor de backend de búsqueda web, lo que aumenta un 48% el rendimiento de búsqueda de nuestras unidades flash y permite que aumente un 40% el rendimiento de todo el backend de búsqueda.
|
| Mapa de calor de solicitudes de IO (resultantes de pérdidas de caché) en todas las hojas del servidor de búsqueda web. Las tres concentraciones representan una selección de hojas aleatoria, balanceo de carga y balanceo de carga basado en caché (de izquierda a derecha). Las líneas indican los percentiles 50, 90, 95 y 99,9. Fuente: Artículo «Balanceo de carga basado en caché en aplicaciones de centros de datos«, de VLDB’19. |
En un artículo de ICLR’2019 titulado «Trucos nuevos para un perro viejo: el aprendizaje por refuerzo encuentra algoritmos de optimización clásicos«, descubrimos una nueva conexión entre los algoritmos y el aprendizaje automático, y mostramos cómo el aprendizaje por refuerzo puede encontrar efectivamente algoritmos óptimos (o, en el peor de los casos, uniformes) para varios problemas combinatorios clásicos de optimización en línea, como el emparejamiento y la asignación en línea.
Nuestro trabajo en algoritmos escalables abarca aquellos que son paralelos, los que se encuentran en línea y los distribuidos para grandes conjuntos de datos. En un artículo de FOCS’19 reciente, proporcionamos un algoritmo casi óptimo de procesamiento masivamente paralelo para componentes conectados. Otros de nuestros artículos mejoraron los algoritmos paralelos para el emparejamiento (en la teoría y en la práctica) y el clúster de densidad. Otra línea de nuestro trabajo se centra en la optimización adaptativa de funciones submodulares en el modelo de caja negra, que tiene varias aplicaciones en la selección de funciones y la compresión de vocabulario. En un artículo de SODA’19, presentamos un algoritmo de maximización submodular que es casi óptimo en tres aspectos: factor de aproximación, complejidad de la función circular y complejidad de búsqueda. Además, en otro artículo de FOCS 2019, proporcionamos el primer algoritmo de aproximación multiplicativa en línea para la selección de análisis de componentes principales y de subconjuntos de columnas.
En otro trabajo, presentamos el modelo informático semi en línea que postula que el futuro desconocido tiene una parte predecible y otra antagonista. Para problemas combinatorios clásicos, como el apareamiento bipartito (ITCS’19) y el almacenamiento en caché (SODA’20), obtuvimos algoritmos semi en línea que proporcionan garantías que interpolan de manera óptima los mejores algoritmos en línea y sin conexión posibles.
Nuestra reciente investigación en el área de trading algorítmico incluye nuevos conocimientos sobre la interacción entre el aprendizaje y los mercados, así como innovaciones en el diseño experimental. Por ejemplo, en este artículo oral de NeurIPS’19, se revela la sorprendente ventaja competitiva que tiene un agente estratégico cuando compite contra un agente de aprendizaje en un juego para 2 jugadores general repetido. El enfoque reciente en la automatización de la publicidad aumentó el interés en las ofertas automáticas y la comprensión del comportamiento de respuesta de los anunciantes. En un par de artículos de WINE 2019, estudiamos la estrategia óptima para maximizar conversiones en nombre de los anunciantes y aprendimos más sobre el comportamiento de respuesta de los anunciantes ante los cambios en las subastas. Por último, estudiamos el diseño experimental en casos de interferencia, en los que el tratamiento de un grupo puede afectar el resultado de otros. En un artículo de KDD’19 y otro de NeurIPS’19, mostramos cómo definir unidades o clústeres de unidades para limitar la interferencia manteniendo la potencia experimental.
 |
| El algoritmo de clúster del artículo de KDD’19 «Diseño experimental aleatorizado mediante clústeres geográficos» se aplicó a búsquedas de usuarios de Estados Unidos. El algoritmo identifica automáticamente las áreas metropolitanas y predice correctamente, por ejemplo, que el Área de la Bahía incluye San Francisco, Berkeley y Palo Alto, pero no Sacramento. |
Algoritmos de aprendizaje automático
En 2019, realizamos una investigación en muchas áreas y enfoques diferentes de los algoritmos de aprendizaje automático. Uno de nuestros principales focos fue la comprensión de las propiedades del entrenamiento de dinámicas en las redes neuronales. En la entrada de blog Medición de los límites del entrenamiento paralelo de datos para redes neuronales, que destaca este artículo, investigadores de Google presentaron un meticuloso conjunto de resultados experimentales que demostraban que escalar el nivel de paralelismo de datos (mediante la creación de lotes más grandes) es efectivo para permitir que el modelo converja más rápido (usando paralelismo de datos).
 |
| En todas las cargas de trabajo que probamos, observamos una relación universal entre el tamaño del lote y la velocidad de entrenamiento con tres regímenes diferentes: el escalamiento perfecto con lotes pequeños (siguiendo la línea de puntos), la disminución en los resultados a medida que crece el tamaño del lote (divergencia de la línea de puntos) y un máximo paralelismo de datos en el caso de los lotes más grandes (donde la tendencia alcanza su meseta). Los puntos de transición entre los regímenes varían de manera significativa entre las diferentes cargas de trabajo. |
A diferencia del paralelismo de modelos, en el que se extiende un modelo en varios dispositivos informáticos, el paralelismo de modelos es una forma efectiva de escalar modelos. GPipe es una biblioteca que habilita el paralelismo de modelos para que sea más efectivo, en un enfoque similar al que implementan los procesadores de CPU de flujo de procesamiento: en él, mientras una parte de todo el modelo trabaja en algunos datos, otras pueden trabajar en su parte del cálculo con otros datos. Los resultados de este flujo de procesamiento pueden combinarse para simular un tamaño de lote efectivo más grande.
Los modelos de aprendizaje automático son efectivos cuando pueden tomar datos de entrada sin procesar y aprender a «desglosar» representaciones más precisas que separen los distintos tipos de ejemplos en función de las propiedades que queremos que ese modelo pueda distinguir (gato vs. camión vs. ñu, tejido canceroso vs. tejido normal, etcétera). Gran parte del objetivo del avance de los algoritmos de aprendizaje automático es impulsar el aprendizaje de mejores representaciones que generalicen con más eficacia los nuevos ejemplos, problemas o dominios. Este año, abordamos este problema desde varios contextos diferentes:
- En Cómo evaluar el aprendizaje sin supervisión de las representaciones desglosadas,examinamos las propiedades que afectan las representaciones que se aprenden a partir de datos sin supervisión a fin de comprender mejor cómo se logran representaciones de calidad y aprendizaje efectivo.
- En Cómo predecir la brecha de generalización en redes neuronales profundas,mostramos que es posible predecir la brecha de generalización (que existe entre el rendimiento de un modelo con datos de la distribución de entrenamiento en comparación con los datos obtenidos a partir de una distribución diferente) usando estadísticas de la distribución de margen, lo que nos ayuda a comprender mejor qué modelos generalizan con mayor efectividad. También investigamos Cómo mejorar la detección sin distribución en modelos de aprendizaje automáticopara comprender mejor cuándo un modelo comienza a encontrar tipos de datos que no había visto antes. Por otro lado, analizamos la Clasificación sin políticas en el contexto del aprendizaje de refuerzo a fin de entender qué modelos son mejores para generalizar.

- En Cómo aprender a generalizar a partir de recompensas dispersas y sin especificar,examinamos métodos para especificar funciones de recompensa para el aprendizaje de refuerzo que les permitan a los sistemas de aprendizaje aprender directamente de objetivos verdaderos a fin de que no pierdan tiempo con secuencias de acciones más extensas y no convenientes que permiten alcanzar los objetivos esperados solo por casualidad.

En esta tarea de seguimiento de instrucciones, la acción traza trayectorias para1,2 y3 a fin de alcanzar el objetivo, pero las secuencias2 y3 no siguen las instrucciones. Este ejemplo ilustra el problema de recompensas sin especificar.


AutoML
Este año continuamos con nuestro trabajo en AutoML. En este enfoque, los algoritmos que aprenden el proceso de aprendizaje pueden automatizar varios aspectos del aprendizaje automático y, con frecuencia, pueden obtener resultados sustancialmente mejores que los mejores expertos humanos en aprendizaje automático para ciertos tipos de metadecisiones de ese campo. En particular:
- En EfficientNet: mejora de la precisión y eficiencia mediante AutoML y el escalamiento de modelos,mostramos cómo usar técnicas de búsqueda de arquitectura neuronal para obtener resultados sustancialmente mejores para problemas de visión artificial, incluido un resultado innovador de precisión de 84,4% top-1 en ImageNet que tenía 8 veces menos parámetros que el mejor modelo anterior.

Tamaño del modelo vs. comparación de precisión: EfficientNet-B0 es la red de modelo de referencia desarrollada por AutoML MNAS, mientras que Efficient-B1 a B7 se obtienen escalando la red de modelo de referencia. En particular, EfficientNet-B7 logra una innovadora precisión de 84,4% top-1/97,1% top-5 y es 8,4 veces menor que la mejor CNN existente. - En EfficientNet-EdgeTPU: cómo crear redes neuronales optimizadas por acelerador con AutoML,mostramos cómo un enfoque de búsqueda de arquitectura neuronal puede encontrar modelos eficientes adaptados a determinados aceleradores de hardware, lo que da como resultado modelos altamente precisos y que requieren poco procesamiento para ejecutarse en dispositivos móviles.
- En Búsqueda de arquitectura de video,describimos cómo extender el trabajo de AutoML al dominio de los modelos de video mediante la búsqueda de arquitecturas que logren resultados innovadores y de arquitecturas livianas que tengan el mismo rendimiento que los modelos manuales, pero reduciendo 50 veces el procesamiento.

Las arquitecturas de TinyVideoNet (TVN) evolucionaron para maximizar el rendimiento de reconocimiento manteniendo el tiempo de procesamiento dentro del límite deseado. Por ejemplo, TVN-1 (arriba) se ejecuta en 37 ms en una CPU y en 10 ms en una GPU. TVN-2 (abajo) se ejecuta en 65 ms en una CPU y en 13 ms en una GPU. - Desarrollamos técnicas de AutoML para datos tabulares, con lo que se desbloqueó un importante dominio en el que muchas empresas y organizaciones tienen interesantes datos en torno a bases de datos relacionales y, con frecuencia, quieren desarrollar modelos de aprendizaje automático sobre estos datos. Colaboramos para lanzar esta tecnología como un nuevo producto de AutoML Tables en Google Cloud y también debatimos qué tan bien funcionó este sistema en una competencia de Kaggle en Solución de extremo a extremo de AutoML para datos tabulares en KaggleDays (spoiler: AutoML Tables quedó en segundo lugar entre 74 equipos de científicos de datos expertos).
- En Cómo explorar redes neuronales sin importar el peso,mostramos cómo es posible encontrar arquitecturas de redes neuronales interesantes sin realizar pasos de entrenamiento para actualizar los pesos de los modelos evaluados. De esta manera, el proceso de búsqueda de arquitectura es mucho más eficiente.


Una red neuronal en la que no importa el peso realiza una tarea con un carro con una vara hacia arriba en diferentes parámetros de peso y también usando parámetros de peso específicos. - Cómo aplicar AutoML en arquitecturas Transformer explora la búsqueda de arquitecturas para el procesamiento de tareas de lenguaje natural cuyo rendimiento supera considerablemente el de los modelos «vanilla Transformer», ya que sus costos de procesamiento eran mucho menores.

Comparación entre el Transformer evolucionado (ET) y el original en WMT’14 En-De, en diferentes tamaños. Los mejores niveles de rendimiento ocurren en los tamaños más pequeños, aunque ET también se muestra sólido en tamaños más grandes y supera el rendimiento del Transformer más grande con un 37,6% menos de parámetros (los modelos comparados se muestran rodeados por un círculo verde). Consulta los valores exactos en la tabla 3 de nuestro artículo. - En SpecAugment: Un nuevo método de aumento de datos para el reconocimiento de voz automático,mostramos que el enfoque de los métodos de aumento de los datos de aprendizaje automático puede extenderse a los modelos de reconocimiento de voz, ya que el enfoque de aumento aprendido logró una precisión mucho mayor con menos datos que los enfoques de aumento de datos impulsados por seres humanos expertos en aprendizaje automático.
- Lanzamos nuestra primera aplicación de identificación de presiones en el teclado y lenguaje hablado mediante AutoML. En nuestros experimentos, encontramos mejores modelos (más eficientes y con mejor rendimiento) que los diseñados por seres humanos que se habían implementado durante un tiempo.





Comprensión del lenguaje natural
Durante los últimos años, vimos grandes avances en los modelos de comprensión del lenguaje natural, traducción, diálogo natural, reconocimiento de voz y tareas relacionadas. Este año, parte de nuestro trabajo generó avances innovadores mediante la combinación de modalidades o tareas para entrenar modelos más potentes y capaces. Ejemplos:
- En Cómo explorar la traducción automática neuronal masiva y multilingüe,mostramos mejoras significativas en la calidad de traducción mediante el entrenamiento de un único modelo que traduzca entre 100 idiomas en lugar de tener 100 modelos separados.


Izquierda: En general, los pares de idiomas con grandes cantidades de datos de entrenamiento tienen mejor calidad de traducción. Derecha: El entrenamiento multilingüe, en el que entrenamos un único modelo para todos los pares de idiomas en lugar tener modelos separados para cada par, presenta mejoras sustanciales en la puntuación BLEU (una medida de calidad de traducción) para pares de idiomas sin muchos datos. - En Reconocimiento de voz multilingüe a gran escala con un modelo de transmisión de extremo a extremo,explicamos cómo podemos mejorar significativamente la precisión del reconocimiento de voz combinando reconocimiento de voz y modelos de idioma, y entrenando el sistema en varios idiomas.

Izquierda: Sistema de reconocimiento de voz monolingüe tradicional compuesto por modelos de idioma, acústica y pronunciación para cada idioma. Centro: Sistema de reconocimiento de voz multilingüe tradicional en el que el modelo de acústica y pronunciación es multilingüe, pero el de idioma es específico por idioma. Derecha: Sistema de reconocimiento de voz de extremo a extremo multilingüe en el que los modelos de idioma, acústica y pronunciación se combinan en un único modelo multilingüe. - En Translatotron: modelo de traducción de voz a voz y de extremo a extremo,mostramos que es posible entrenar un modelo combinado para lograr que las tareas (normalmente independientes) de reconocimiento de voz, traducción y generación de texto a voz logren interesantes beneficios, como preservar el sonido de la voz del emisor en el audio traducido que se genera y simplificar el sistema general de aprendizaje.
- En Codificador universal de oraciones multilingües para la obtención semántica,mostramos cómo combinar diversos objetivos para crear modelos que sean significativamente mejores en la obtención semántica (en comparación con técnicas de combinación de palabras más simples). Por ejemplo, en Google habla con los libros, la búsqueda«¿Qué aroma evoca recuerdos?«genera el resultado«A mí, el aroma del jazmín y el del pan bagnat me hacen recordar mi tranquila niñez».
- En Traducción automática neuronal robusta,mostramos cómo usar un procedimiento de entrenamiento antagonista para mejorar significativamente la calidad y la robustez de las traducciones.


Izquierda: Se aplica el modelo Transformer a una oración de entrada(abajo, izquierda)y, junto con la oración de salida en el idioma de destino (arriba, derecha)y la oración de entrada en el idioma de destino(centro, derecha;comienza con el marcador de posición «<sos>»), se calcula la pérdida de traducción. La función AdvGen toma la oración de origen, la distribución de la selección de palabras, las palabras candidatas y la pérdida de traducción como entradas para construir un ejemplo de origen antagonista. Derecha: En la etapa de defensa, el texto de origen antagonista funciona como entrada del modelo Transformer, y se calcula la pérdida de traducción. Luego, AdvGen usa el mismo método anterior para generar un ejemplo de texto de destino antagonista a partir de la entrada en el idioma de destino.





Como nuestra capacidad de comprender el idioma mejoró, en función de avances de investigación fundamentales como los modelos seq2seq, Transformer, BERT, Transformer-XL y ALBERT, notamos un aumento en el uso de este tipo de modelos en varios de nuestros principales productos y funciones, como Google Traductor, Redacción inteligente de Gmail y la Búsqueda de Google. Este año, el lanzamiento de BERT en nuestros algoritmos de búsqueda y clasificación centrales dio lugar a la más grande mejora en la calidad de búsqueda de los últimos años (y una de las principales de la historia) mediante una mejor comprensión de los significados sutiles de una búsqueda y las frases y palabras de los documentos.
Percepción automática
Los modelos para comprender mejor las imágenes estáticas tuvieron un considerable progreso en la última década. Las próximas fronteras se encuentran en los modelos y los enfoques para comprender mejor el mundo dinámico a nivel más preciso. Eso incluye una comprensión más profunda y detallada de imágenes y videos, y una percepción en tiempo real y en contexto: comprender el mundo audiovisual a nivel interactivo y con un vínculo espacial compartido con el usuario. Este año, exploramos varios aspectos que avanzaron en esta área, por ejemplo:
- Comprensión más detallada a nivel visual en Lens que permitió potenciar la búsqueda visual
- Funciones útiles para la cámara inteligente, como los gestos rápidos, Face Match y enmarcado inteligente para videollamadas en Nest Hub Max
- Tecnología para la percepción del espacio en tiempo real para aumentar de manera útil el mundo que nos rodea con Lens
- Mejores modelos para la predicción futura a partir de videos
- Mejores representaciones para la comprensión temporal detallada de videos mediante aprendizaje temporal consistente y cíclico

Derecha: Entrada de videos de personas que realizan un ejercicio de sentadillas. El video en la parte superior izquierda es la referencia. Los otros videos muestran los fotogramas más similares (en el espacio de incorporaciones de TCC) de otros videos de personas que hacen sentadillas. Izquierda: Las incorporaciones de fotogramas correspondientes avanzan a medida que se realiza la acción. - Aprendizaje de representaciones en texto, voz y video que son temporalmente coherentes a partir de videos sin referencia.

Resultados cualitativos de VideoBERT preentrenados en videos de cocina Arriba: Con algo de texto sobre recetas, generamos una secuencia de tokens visuales. Abajo: Con un token visual, mostramos los tres principales tokens futuros que predice VideoBERT en diferentes escalas de tiempo. En ese caso, el modelo predice que un bol de harina y polvo de cacao puede hornearse y convertirse en un pastel o un brownie. Visualizamos los tokens visuales con las imágenes del conjunto de entrenamiento más similar a los tokens en el espacio correspondiente. - Desarrollamos la capacidad para predecir entradas visuales futuras a partir de observaciones pasadas.
- Creamos modelos que comprenden mejor las secuencias de acciones en videos, lo que permite recordar mejor los momentos especiales de los videos, como «soplar velas» o «bajar por el tobogán», en Google Fotos.

Desarrollamos arquitectura para la localización de acciones temporal.



Nos entusiasman los prospectos de las continuas mejoras en la comprensión del mundo sensorial que nos rodea.
Robótica
La aplicación del aprendizaje automático en controles de robótica es una importante área de investigación para nosotros. Creemos que es una herramienta vital para que los robots operen de manera efectiva en entornos complejos del mundo real, como los hogares y las empresas. Estos son algunos ejemplos de nuestro trabajo de este año:
- En Navegación robótica de largo alcance mediante aprendizaje de refuerzo automatizado,mostramos cómo combinar aprendizaje de refuerzo con planificación de largo alcance para que los robots naveguen en entornos complejos (como los edificios de oficinas de Google) de manera eficaz.

- En PlaNet: una red profunda de planificación para el aprendizaje reforzado,mostramos cómo aprender de manera efectiva un modelo del mundo solo a partir de los píxeles de imágenes y cómo implementar este modelo sobre el comportamiento del mundo para realizar tareas con menos sesiones de aprendizaje.
- En Unificación de la física y el aprendizaje profundo con TossingBot,mostramos cómo los robots pueden aprender física «intuitiva» a partir de la experimentación en un entorno en lugar de programarse previamente con modelos de física sobre el entorno en el que operan.

- En Soft Actor-Critic: aprendizaje de refuerzo profundo para la robótica,mostramos que entrenar un algoritmo de aprendizaje de refuerzo para maximizar la recompensa esperada (que es el objetivo estándar de este aprendizaje) y la entropía de la política (para que el aprendizaje favorezca las políticas más aleatorias) puede ayudar a los robots a aprender más rápido y ser más robustos ante los cambios del entorno.

- En Cómo aprender a ensamblar y generalizar a partir de la separación autosupervisada,mostramos cómo los robots pueden aprender a ensamblar si primero aprenden a separar los elementos de manera controlada. Los niños aprenden cuando desarman y, al parecer, ¡los robots también!

- Presentamos ROBEL: comparativas de robótica para el aprendizaje con robots económicos,una plataforma de código abierto que tiene robots rentables y comparativas seleccionadas que se diseñaron para facilitar la búsqueda y el desarrollo de hardware de robótica física en el mundo real.




{kind=link}
{kind=link}
Contribuimos al avance de la comunidad general de investigadores y desarrolladores
El código abierto no es solo eso: también involucra a la comunidad de colaboradores. Fue muy gratificante ser parte este año de la comunidad de código abierto. Lanzamos TensorFlow 2.0 (el más grande hasta la fecha), que compila sistemas y aplicaciones de aprendizaje automático con más facilidad que nunca. Agregamos compatibilidad con inferencia de GPU para dispositivos móviles más rápida a TensorFlow Lite. También lanzamos Teachable Machine 2.0, una herramienta web rápida y fácil que puede entrenar un modelo de aprendizaje automático con un solo clic y no requiere código. Anunciamos MLIR, una infraestructura compiladora de aprendizaje automático de código abierto que resuelve la complejidad de la creciente fragmentación de software y hardware, y facilita la compilación de aplicaciones de IA.
Cumplió un año JAX, el nuevo sistema de investigación de aprendizaje automático de alto rendimiento. En NeurIPS 2019, los empleados de Google y la comunidad general de código abierto presentaron trabajos en los que usaron JAX y que abarcaron, por ejemplo kernels de tangente neuronal, inferencia bayesiana y dinámica molecular, y lanzamos una vista previa de JAX en TPU de Cloud.
Habilitamos MediaPipe con código abierto, un marco de trabajo para compilar flujos de procesamiento de aprendizaje automático perceptuales y multimodales aplicados, y XNNPACK, una biblioteca de eficaces operadores de inferencia de redes neuronales de punto flotante. A fines de 2019, permitimos que más de 1500 investigadores de todo el mundo accedieran a TPU de Cloud de manera gratuita a través de TensorFlow Research Cloud. Nuestra Introducción a TensorFlow en Coursera llegó a 100 000 estudiantes. Además, nos acercamos a miles de usuarios cuando viajamos para mostrar TensorFlow a 11 países, celebramos nuestro primer TensorFlow World y mucho más.
Con ayuda de TensorFlow, una estudiante universitaria descubrió dos planetas nuevos y compiló un método para ayudar a otros a descubrir más. Un científico de datos originario de Nigeria entreno un GAN para generar imágenes que representaban máscaras africanas. Una desarrolladora de Uganda usó TensorFlow para crear Farmers Companion, una app que los agricultores locales pueden usar para acabar con una oruga que amenaza sus cultivos. En la nevada Iowa, investigadores y funcionarios estatales usaron TensorFlow para determinar las condiciones de seguridad del camino en función del comportamiento del tráfico, la información visual y otros datos. En la soleada California, estudiantes universitarios usaron TensorFlow para detectar baches y grietas peligrosas en caminos de Los Ángeles. Por último, en Francia, un codificador usó TensorFlow para compilar un algoritmo simple que aprende cómo agregar color a las fotos en blanco y negro.
Conjuntos de datos abiertos
Los conjuntos de datos abiertos con objetivos claros y medibles suelen ser muy útiles para lograr avances en el campo del aprendizaje automático. Para ayudar a la comunidad investigadora a encontrar conjuntos de datos interesantes, seguimos indexando una gran variedad de conjuntos de datos abiertos de diferentes organizaciones mediante Google Búsqueda de Datasets. También creemos que es importante crear nuevos conjuntos de datos para que la comunidad explore y desarrolle nuevas técnicas, y para asegurarnos de compartir de manera responsable los datos abiertos. Este año, además, lanzamos varios conjuntos de datos abiertos en diversas áreas:
- Open Images V5: Una actualización para el popular conjunto de datos Open Images que incluye máscaras de segmentación para 2,8 millones de objetos de 350 categorías (de modo que ahora tiene cerca de 9 millones de imágenes anotadas con etiquetas a nivel de imagen, cuadros para vincular objetos, máscaras de segmentación de objetos y relaciones visuales).
- Preguntas naturales: Primer conjunto de datos que usa búsquedas que ocurren naturalmente y encuentra respuestas mediante la lectura de una página completa en lugar de extraer respuestas de un párrafo breve.
- Datos para la detección de ultrafalsos: Contribuimos con un gran conjunto de datos de ultrafalsos visuales en la comparativa FaceForensics (mencionada anteriormente).
- Google Research para fútbol: Entorno de aprendizaje de refuerzo novedoso en el que los agentes buscan dominar el deporte más popular del mundo: el fútbol (en EE.UU., «soccer»). En este caso, los agentes de aprendizaje de refuerzo salen a la cancha.
- Google-Landmarks-v2: Más de 5 millones de imágenes (el doble que la primera versión) de más de 200 000 lugares diferentes.
- YouTube-8M Segments: Conjunto de datos de localización temporal y clasificación a gran escala que incluye etiquetas verificadas por seres humanos en el nivel de segmento de 5 segundos de los videos de YouTube-8M.
- Actividades de voz de Atomic Visual Actions (AVA): Conjunto de datos de video multimodal de audio y contenido visual para la percepción de conversaciones. Además, ejecutamos desafíos académicos para el reconocimiento de acciones de AVA y AVA: actividades de voz
- PAWS y PAWS-X: Para ayudar en la identificación de paráfrasis, ambos conjuntos de datos contienen pares de oraciones correctas con amplia superposición léxica; la mitad de los pares son paráfrasis y la otra mitad no.
- Conjuntos de datos de diálogo de lenguaje natural: CCPE y Taskmaster-1 usan una plataforma Wizard-of-Oz que empareja a dos personas que conversan para imitar una charla de nivel humano con un asistente digital.
- Comparativa de adaptación de tareas visuales (VTAB): VTAB sigue lineamientos similares a ImageNet y GLUE, pero se basa en el principio de que una mejor representación es aquella que tiene un mejor rendimiento para las tareas nuevas con datos de dominio limitados.
- Conjunto de datos de diálogo guiados por Schema: El más grande de los corpus públicos de diálogos orientados por tarea disponibles, que contiene más de 18 000 diálogos en 17 dominios.
Interacción con la comunidad de investigación
Finalmente, estuvimos ocupados con la comunidad académica y de investigación general. En 2019, investigadores de Google presentaron cientos de artículos, participaron en muchas conferencias y recibieron varios premios y otros galardones. Tuvimos una importante presencia en los siguientes eventos:
- CVPR: Cerca de 250 empleados de Google presentaron más de 40 artículos, charlas, carteles, talleres y mucho más.
- ICML: Cerca de 200 empleados de Google presentaron más de 100 artículos, charlas, carteles, talleres y mucho más.
- ICLR: Cerca de 200 empleados de Google presentaron más de 60 artículos, charlas, carteles, talleres y mucho más.
- ACL: Cerca de 100 empleados de Google presentaron más de 40 artículos, instructivos y talleres.
- Interspeech: Más de 100 empleados de Google presentaron más de 30 artículos.
- ICCV: Cerca de 200 empleados de Google presentaron más de 40 artículos, y varios ganaron tres prestigiosos premios de ICCV.
- NeurIPS: Cerca de 500 empleados de Google participaron como autores en más de 120 artículos aceptados y participaron en talleres y mucho más.
También reunimos a cientos de investigadores de Google y docentes de todo el mundo en 15 talleres de investigación individuales realizados en sedes de Google. Esos talleres abordaron temas como mejorar la predicción de inundaciones a nivel global; usar el aprendizaje automático para compilar sistemas que puedan serles más útiles a las personas con discapacidades; y acelerar el desarrollo de algoritmos, aplicaciones y herramientas para procesadores cuánticos ruidosos de escala intermedia (NISQ).
En apoyo a comunidades de investigación y academias ajenas a Google, subsidiamos a más de 50 estudiantes de doctorado de todo el mundo con nuestro programa «PhD Fellowship Program», financiamos 158 proyectos como parte de nuestros premios Google Faculty Research 2018 y realizamos una tercera cohorte del programa de residencias de Google IA. También trabajamos como mentores para startups dedicadas a la IA.
Nuevos lugares y nuevos rostros
Dimos un gran paso en 2019, pero todavía podemos hacer mucho más. Para seguir ampliando nuestro impacto en todo el mundo, abrimos una oficina de investigación en Bangalore y nos estamos expandiendo en otras oficinas. Si deseas trabajar para resolver estos problemas, te interesará saber que estamos contratando.
Expectativas para 2020 y más allá
La última década nos dejó grandes avances en los campos del aprendizaje automático y la informática, ya que les dimos a las computadoras la capacidad de ver, oír y entender nuestro lenguaje mejor que nunca (consulta el interesante resumen de los avances importantes de la última década). Ahora tenemos en el bolsillo sofisticados dispositivos informáticos que pueden usar estas capacidades para ayudarnos a realizar varias tareas de nuestra vida de manera más eficaz. Rediseñamos sustancialmente nuestras plataformas de procesamiento en torno a estos enfoques de aprendizaje automático mediante el desarrollo de hardware especializado, lo que nos permitió resolver problemas aún más complejos. Estos avances cambiaron nuestra visión sobre los dispositivos de procesamiento tanto en los centros de datos (como el TPUv1 basado en la inferencia y los TPUv2 y TPUv3 basados en el entrenamiento y la inferencia) como en los entornos móviles de bajo consumo (como Edge TPU). La revolución del aprendizaje profundo continuará cambiando nuestra visión sobre la informática y las computadoras.
Sin embargo, todavía quedan muchas preguntas sin respuesta y problemas sin resolver. Algunas direcciones y respuestas que esperamos encontrar en 2020 y el futuro son las siguientes:
- ¿Cómo podemos compilar sistemas de aprendizaje automático que puedan realizar millones de tareas y aprendan correctamente otras nuevas de manera automática? Actualmente, entrenamos sobre todo modelos automáticos separados para cada tarea nueva: empezamos de cero o, como mucho, con un modelo entrenado en una tarea o en unas pocas tareas muy relacionadas. Por lo tanto, los modelos que entrenamos son muy buenos en una o dos tareas, pero no más. Sin embargo, lo que realmente buscamos son modelos que sean buenos para implementar sus conocimientos en la realización de varias tareas a fin de que puedan aprender una nueva con relativamente pocos datos de entrenamiento y procesamiento. Este es un gran desafío que requerirá conocimientos y avances en varias áreas, por ejemplo, diseño de circuitos de estado sólido, arquitectura de computadoras, compiladores basados en aprendizaje automático, sistemas distribuidos y algoritmos de aprendizaje automático, y expertos en dominios de muchos otros campos a fin de compilar sistemas que puedan generalizar y resolver nuevas tareas de manera independiente en una amplia variedad de áreas.
- ¿Cómo podemos avanzar e innovar en áreas importantes de la investigación de inteligencia artificial, por ejemplo, prevención de sesgos, aumento de la interpretabilidad y la comprensibilidad, mejoras en la privacidad y garantía de seguridad? El avance en esas áreas será fundamental, ya que cada vez usamos más el aprendizaje automático en la sociedad.
- ¿Cómo podemos aplicar la informática y el aprendizaje automático para realizar avances en importantes áreas nuevas de la ciencia? Se requieren importantes avances mediante la colaboración con expertos en otros campos, como climatología, cuidado de la salud, bioinformática y muchas otras áreas.
- ¿Cómo podemos asegurarnos de que las ideas y las direcciones en las que pongan su atención las comunidades de aprendizaje automático y de investigación informática se pongan en práctica y sean exploradas por diversos grupos de investigadores? El trabajo al que se dedican las comunidades de investigación informática y de aprendizaje automático tiene grandes implicancias para miles de millones de personas, y queremos que los grupos de investigadores que realizan ese trabajo representen las experiencias, las perspectivas, los intereses y el entusiasmo creativo de todo el mundo. ¿Cómo podemos apoyar mejor a los nuevos investigadores de diferentes entornos que ingresen al campo?
En resumen, 2019 fue un año muy emocionante para los investigadores de Google y la comunidad de investigación general. Estamos ansiosos por resolver los desafíos de investigación que nos esperan en 2020 y más allá, ¡y esperamos compartir nuestro progreso con ustedes!
Source: Google Dev